iOS相关基础看这篇就够了
响应链
知识点:Responder相关的子类、Runloop
常见提问:在屏幕上点击一个按钮发生了什么?
响应链上的相关继承关系,你为什么可以响应?
继承至UIResponder的才可以响应
- NSObject->UIResponder->UIView->UIControl->UIButton
- NSObject->UIResponder->UIApplication
- NSObject->UIResponder->UIViewController
详细继承图见:UI继承结构图
需要记住的方法特点:
- UIResponder:touch press motion responder
- UIView:hitTest: pointInside:
- UIControl: addTarget
点击屏幕之后的整个流程
- 硬件捕捉到用户点击
- IOKit.framework封装IOHIDEvent对象,通过mach port转发到SpringBoard.app,然后接着通过mach port转发给当前app的主线程(IPC进程间通信)
- RunLoop 的source1触发,source1触发source0回调,封装为UIEvent,并放到当前活动的application的事件队列中,整个event自下而上传递
- application->window->hittest->view->hittest->button 找到第一响应者
之后响应链开始从上往下nextResponder响应:第一响应者 -> 父视图 -> 视图控制器 直到UIApplication都没响应则丢弃
- UITextField ——> UIView ——> UIView ——> UIViewController ——> UIWindow ——> UIApplication ——> UIApplicationDelegation
- 如果button上面叠加添加了手势,手势会覆盖住不执行target方法,除非设置手势的cancelsTouchesInView = NO 如果button上有subview,subview需要设置userInteractionEnabled=NO
Source0:用户主动触发的事件(点击button或是点击屏幕)–非基于Port的
Source1:通过内核和其他线程相互发送消息(与内核相关)–基于Port的
touch方法传递到control(uibutton)就不会再往上传递,如果需要传递,需要手动,[self.nextResponder touchesBegan:touches withEvent:event],响应链不受这个影响
两个链
事件传递链,自下而上。hit-testing
响应链,自上而下传递。nextResponder
可能的面试题
- 触摸事件由触屏生成后如何传递到当前应用?
- 触摸事件从触屏产生后,由IOKit将触摸事件传递给SpringBoard进程,再由SpringBoard分发给当前前台APP处理。
- 应用接收触摸事件后如何寻找最佳响应者?实现原理?
- Hit-testing过程,自下由上application->window->hittest->view->hittest->button 找到第一响应者。主要实现方法是
- (UIView *)hitTest:(CGPoint)point withEvent:(UIEvent *)event方法。里面判断逻辑不透明不是隐藏不是不可交互,判断point是否在自己身上pointInside:withEvent:,在的话在判断子view(也就是向上),从后向前遍历子view。
- Hit-testing过程,自下由上application->window->hittest->view->hittest->button 找到第一响应者。主要实现方法是
- 触摸事件如何沿着响应链流动?
- 找到响应者之后,通过复写touch方法去响应停止向下传递。如果没有响应,事件随着响应链nextResponder找到响应者。UITextField ——> UIView ——> UIView ——> UIViewController ——> UIWindow ——> UIApplication ——> UIApplicationDelegation
- 响应链、手势识别器、UIControl之间对于触摸事件的响应有着什么样的瓜葛?
实际应用
按钮点击没有响应
按钮的父view是UIImageView,imageView的userInteractionEnabled默认是false
父view忘记设置frame,因为没有设置clipTobounds,子view在这种时候也是能够显示出来的
扩展一个按钮的点击区域
巧妙使用覆写pointInside:withEvent:方法
其他
按钮、手势同时覆盖,哪个响应先后的逻辑挺恶心的,可以自行写demo试试
贴一段hittest代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
- (UIView *)hitTest:(CGPoint)point withEvent:(UIEvent *)event{
//3种状态无法响应事件
if (self.userInteractionEnabled == NO || self.hidden == YES || self.alpha <= 0.01) return nil;
//触摸点若不在当前视图上则无法响应事件
if ([self pointInside:point withEvent:event] == NO) return nil;
//从后往前遍历子视图数组
int count = (int)self.subviews.count;
for (int i = count - 1; i >= 0; i--)
{
// 获取子视图
UIView *childView = self.subviews[i];
// 坐标系的转换,把触摸点在当前视图上坐标转换为在子视图上的坐标
CGPoint childP = [self convertPoint:point toView:childView];
//询问子视图层级中的最佳响应视图
UIView *fitView = [childView hitTest:childP withEvent:event];
if (fitView)
{
//如果子视图中有更合适的就返回
return fitView;
}
}
//没有在子视图中找到更合适的响应视图,那么自身就是最合适的
return self;
}
消息转发
所有方法调用在编译之后都是objc_msgSend相关方法
知识点:
1
2
3
4
5
struct objc_object
struct objc_class : objc_object
typedef struct objc_class *Class;
typedef struct objc_object *id;
OC是分两个版本
- Objective-C 1.0,已经废弃了不用了
- Objective-C 2.0,现在在使用的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
// objc-private.h
struct objc_object {
// isa结构体
private:
isa_t isa;
public:
// ISA() assumes this is NOT a tagged pointer object
Class ISA();
// 下面一堆其他方法
}
// objc-runtime-new.h
// objc_class继承于objc_object,因此
// objc_class中也有isa结构体
struct objc_class : objc_object {
// ISA占8位
// Class ISA;
// superclass占8位
Class superclass;
// 缓存的是指针和vtable,目的是加速方法的调用 cache占16位
cache_t cache; // formerly cache pointer and vtable
// class_data_bits_t 相当于是class_rw_t 指针加上rr/alloc标志
class_data_bits_t bits;
// 类的方法、属性、协议等信息都保存在class_rw_t结构体中
class_rw_t *data() {
// 这里的bits就是class_data_bits_t bits;
return bits.data();
}
void setData(class_rw_t *newData) {
bits.setData(newData);
}
// 下面一堆其他方法
}
// 类的方法、属性、协议等信息都保存在class_rw_t结构体中
struct class_rw_t {
// Be warned that Symbolication knows the layout of this structure.
uint32_t flags;
uint32_t version;
// class_ro_t结构体存储了类在编译期就已经确定的属性、方法以及遵循的协议
const class_ro_t *ro;
// 方法信息
method_array_t methods;
// 属性信息
property_array_t properties;
// 协议信息
protocol_array_t protocols;
Class firstSubclass;
Class nextSiblingClass;
char *demangledName;
#if SUPPORT_INDEXED_ISA
uint32_t index;
#endif
void setFlags(uint32_t set)
{
OSAtomicOr32Barrier(set, &flags);
}
void clearFlags(uint32_t clear)
{
OSAtomicXor32Barrier(clear, &flags);
}
// set and clear must not overlap
void changeFlags(uint32_t set, uint32_t clear)
{
assert((set & clear) == 0);
uint32_t oldf, newf;
do {
oldf = flags;
newf = (oldf | set) & ~clear;
} while (!OSAtomicCompareAndSwap32Barrier(oldf, newf, (volatile int32_t *)&flags));
}
};
// class_ro_t结构体存储了类在编译期就已经确定的属性、方法以及遵循的协议
// 因为在编译期就已经确定了,所以是ro(readonly)的,不可修改
struct class_ro_t {
uint32_t flags;
uint32_t instanceStart;
uint32_t instanceSize;
#ifdef __LP64__
uint32_t reserved;
#endif
const uint8_t * ivarLayout;
const char * name;
// 方法列表
method_list_t * baseMethodList;
// 协议列表
protocol_list_t * baseProtocols;
// 变量列表
const ivar_list_t * ivars;
const uint8_t * weakIvarLayout;
// 属性列表
property_list_t *baseProperties;
method_list_t *baseMethods() const {
return baseMethodList;
}
};
一段oc代码
1
[test by_eat5111];
使用clang进行编译clang -rewrite-objc main.m -o main.cpp之后变成
1
2
3
4
((void (*)(id, SEL))(void *)objc_msgSend)((id)test, sel_registerName("by_eat5111"));
// 简写如下
objc_msgSend(test,sel_registerName("by_eat5111"));
// 其实就是向test对象发送by_eat5111的sel消息
objc_msgSend 的汇编实现,最后调用到
1
2
3
4
5
6
7
8
9
// objc-runtime-new.mm
IMP _class_lookupMethodAndLoadCache3(id obj, SEL sel, Class cls)
{
return lookUpImpOrForward(cls, sel, obj,
YES/*initialize*/, NO/*cache*/, YES/*resolver*/);
}
IMP lookUpImpOrForward(Class cls, SEL sel, id inst,
bool initialize, bool cache, bool resolver)
汇编调用部分总结objc_msgSend流程分析
lookUpImpOrForward讲解见对象方法消息传递流程
总结来说,也是先找缓存,再找方法列表,再找父类的缓存和方法列表,最后没找到就是调用msgForward
objc_objcet.isa ⇒ objc_class.bits.data ⇒ class_rw_t.ro ⇒ class_ro_t.baseMethodList
被问过,对象占多大内存这种问题,蜜汁疑惑,可能是问objc_class的占内存大小吧(40)。
其实考的是内存布局,最后还是问GPT才找到的答案,详细见文章iOS进阶面试2023版本
下面贴下简写版本的 objc_class和objc_object,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
//
// main.cpp
// RAMCPPDemo
//
// Created by rambo on 2020/11/24.
//
#include <iostream>
typedef void (*IMP)(void /* id, SEL, ... */ );
struct objc_class;
struct objc_object;
typedef struct objc_class *Class;
int main(int argc, const char * argv[]) {
struct Test {
int a;
long b;
void test();
void test2();
};
union isa_t {
Class cls;
unsigned long bits;
struct {
unsigned long nonpointer : 1;
unsigned long has_assoc : 1;
unsigned long has_cxx_dtor : 1;
unsigned long shiftcls : 33;
unsigned long magic : 6;
unsigned long weakly_referenced : 1;
unsigned long deallocating : 1;
unsigned long has_sidetable_rc : 1;
unsigned long extra_rc : 19;
};
};
struct bucket_t {
private:
// IMP-first is better for arm64e ptrauth and no worse for arm64.
// SEL-first is better for armv7* and i386 and x86_64.
#if __arm64__
MethodCacheIMP _imp;
cache_key_t _key;
#else
unsigned long _key;
IMP _imp;
#endif
};
struct cache_t {
struct bucket_t *_buckets;
unsigned int _mask;
unsigned int _occupied;
};
struct class_data_bits_t {
unsigned long bits;
};
// 类的方法、属性、协议等信息都保存在class_rw_t结构体中
struct class_rw_t {
// Be warned that Symbolication knows the layout of this structure.
uint32_t flags;
uint32_t version;
// class_ro_t结构体存储了类在编译期就已经确定的属性、方法以及遵循的协议
const class_ro_t *ro;
// 方法信息
method_array_t methods;
// 属性信息
property_array_t properties;
// 协议信息
protocol_array_t protocols;
Class firstSubclass;
Class nextSiblingClass;
char *demangledName;
}
// class_ro_t结构体存储了类在编译期就已经确定的属性、方法以及遵循的协议
// 因为在编译期就已经确定了,所以是ro(readonly)的,不可修改
struct class_ro_t {
uint32_t flags;
uint32_t instanceStart;
// 实例变量大小,决定对象创建时要分配的内存
uint32_t instanceSize;
#ifdef __LP64__
uint32_t reserved;
#endif
const uint8_t * ivarLayout;
// 类名
const char * name;
// (编译时确定的)方法列表
method_list_t * baseMethodList;
// (编译时确定的)所属协议列表
protocol_list_t * baseProtocols;
//(编译时确定的)实例变量列表
const ivar_list_t * ivars;
const uint8_t * weakIvarLayout;
// (编译时确定的)属性列表
property_list_t *baseProperties;
method_list_t *baseMethods() const {
return baseMethodList;
}
};
struct objc_object {
// isa结构体
isa_t isa;
};
struct objc_class : objc_object {
// ISA占8位
// Class ISA;
// superclass占8位
Class superclass;
// 缓存的是指针和vtable,目的是加速方法的调用 cache占16位
cache_t cache; // formerly cache pointer and vtable
// class_data_bits_t 相当于是class_rw_t 指针加上rr/alloc标志 占8位
class_data_bits_t bits; // class_rw_t * plus custom rr/alloc flags
class_rw_t *data() {
// 这里的bits就是class_data_bits_t bits;
return bits.data();
}
};
printf("%lu\n", sizeof(objc_class));//共占 40
return 0;
}
- Objective-C 对象是什么?Class 是什么?id 又是什么?
- isa 是什么?为什么要有 isa?
- 为什么在 Objective-C 中,所以的对象都用一个指针来追踪?
- Objective-C 对象是如何被创建(alloc)和初始化(init)的?
- Objective-C 对象的实例变量是什么?为什么不能给 Objective-C 对象动态添加实例变量?
- Objective-C 对象的属性是什么?属性跟实例变量的区别?
- Objective-C 对象的方法是什么?Objective-C 对象的方法在内存中的存储结构是什么样的?
- 什么是 IMP?什么是选择器 selector ?
- 消息发送和消息转发
- Method Swizzling
- Category
- Associated Objects 的原理是什么?到底能不能在 Category 中给 Objective-C 类添加属性和实例变量?
- Objective-C 中的 Protocol 是什么?
- self 和 super 的本质
- load 方法和 initialize 方法
读 objc4 源码,深入理解 Objective-C Runtime
KVO KVC
KVO
利用RuntimeAPI动态生成一个子类,并且让instance对象的isa指向这个全新的子类
当修改instance对象的属性时,会调用Foundation的_NSsetIntValueAndNotify函数,在这个函数中会调用如下
1
2
3
willChangeValueForKey:
父类原来的setter
didChangeValueForKey: // 内部会触发监听器(Oberser)的监听方法(observeValueForKeyPath:ofObject:change:context:)
想要手动触发KVO,需要先调用willChangeValueForKey再调用didChangeValueForKey
KVC
KVC(key-Value coding) 键值编码,指iOS开发中,可以允许开发者通过Key名直接访问对象的属性,或者给对象的属性赋值。不需要调用明确的存取方法,这样就可以在运行时动态访问和修改对象的属性,而不是在编译时确定。
通过KVC修改属性会触发KVO
找setKey方法->找_setKey方法-> accessInstanceVariablesDirectly(是否可以直接访问成员变量)->_key->_isKey->key->isKey成员变量 getKey->key->isKey->_key方法-> accessInstanceVariablesDirectly->_key、_isKey、key、iskey
valueForUndefinedKey:
setValue:forUndefinedKey:
高阶用法:@avg、@count、@max、@min、@sum、@distinctUnionOfObjects、@unionOfObjects
循环引用
造成循环应用的金典场景
- delegate使用了strong
- vc引用了block,block引用了self
- timer没有释放,这个是timer持有住了self,timer一直在跑所以是没有释放,不是循环引用
- 多层引用, a->b->c->d->b a释放了,但是bcdb循环
@weaikfy(self) 和@strongify(self)宏拆解
#define weakify(self) autoreleasepool{} _weak __typeof__ (self) self_weak = self;
#define strongify(self) autoreleasepool{} _strong __typeof__(self) self = self_weak;
block
block方法被转成了__main_block_impl_0,block的方法体被转成了__main_block_func_0
impl里面就会有一个局部变量,申明的时候传入外部的,这就是捕获
为什么当我们在定义block之后修改局部变量age的值,在block调用的时候无法生效。
因为block在定义的之后已经将age的值传入存储在__main_block_imp_0结构体中并在调用的时候将age从block中取出来使用,因此在block定义之后对局部变量进行改变是无法被block捕获的block内的变量已经是另一个变量了。(block内的变量已经是另一个变量了)
block会进行变量捕获
auto变量-局部变量 会在block内部专门增加一个参数来存储 值传递,因为局部变量可能会被释放
static变量 增加一个参数 指针传递
全局变量不会捕获,因为局部变量因为跨函数访问所以需要捕获,全局变量在哪里都可以访问 ,所以不用捕获
Block, 你为啥要 copy?block为什么要用copy修饰,不用strong?
block 在内存的管理中是被当成栈对象来管理的,用copy就是讲block弄到堆上。ARC中用strong系统会默认帮我去做copy这个动作,但是建议用copy去指出这种内存行为。
__block int age = 0; 变成 __Block_byref_age_0 *age;
实际代码如下,然后其实就是转化为了一个指针,传入的是这个结构体的地址
1
__attribute__((__blocks__(byref))) __Block_byref_age_0 age = {(void*)0,(__Block_byref_age_0 *)&age, 0, sizeof(__Block_byref_age_0), 10}
__block不能修饰全局变量、静态变量(static)
编译器会将__block变量包装成一个对象
block 里面为什么要用strong?
因为不用strong的话,self被释放掉之后执行block里面的self会失败。并且strongself是个局部变量,存在于栈中,而栈中内存系统会自动回收,也就是在block执行结束之后就会回收。.同时strongSelf使Controller的引用计数加1,致其在pop后不会立马执行dealloc销毁str属性,因为此时strongSelf持有了Controller,block执行并打印str,局部变量strongSelf被系统回收,其持有的ControllerB也会执行dealloc方法.
masonry不需要weakify,是因为masonry没有持有住block,block执行完就会被释放
__strong __typeof(wself) sself = wself; 为什么能起到强引用效果?
引用计数描述的是对象而不是指针。sself 强引用 wself 指向的那个对象,因此对象的引用计数会增加一个。
block 内部定义了sself,会不会因此强引用了 sself?
block 只有截获外部变量时,才会引用它。如果是内部新建一个,则没有任何问题。会随block执行结束而释放,因为是局部变量,存在于栈中
如果在 block 内部没有强引用,而是通过 if 判断是否为nil在执行,是不是也可以?
不可以!考虑到多线程执行,也许在判断的时候,self 还没释放,但是执行 self 里面的代码时,就刚好释放了。
Runloop
相关面试问题
线程和runloop的关系
线程和 RunLoop 之间是一一对应的,其关系是保存在一个全局的 Dictionary 里。线程刚创建时并没有 RunLoop,如果你不主动获取,那它一直都不会有。RunLoop 的创建是发生在第一次获取时,RunLoop 的销毁是发生在线程结束时。你只能在一个线程的内部获取其 RunLoop(主线程除外)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
/// 全局的Dictionary,key 是 pthread_t, value 是 CFRunLoopRef
static CFMutableDictionaryRef loopsDic;
/// 访问 loopsDic 时的锁
static CFSpinLock_t loopsLock;
/// 获取一个 pthread 对应的 RunLoop。
CFRunLoopRef _CFRunLoopGet(pthread_t thread) {
OSSpinLockLock(&loopsLock);
if (!loopsDic) {
// 第一次进入时,初始化全局Dic,并先为主线程创建一个 RunLoop。
loopsDic = CFDictionaryCreateMutable();
CFRunLoopRef mainLoop = _CFRunLoopCreate();
CFDictionarySetValue(loopsDic, pthread_main_thread_np(), mainLoop);
}
/// 直接从 Dictionary 里获取。
CFRunLoopRef loop = CFDictionaryGetValue(loopsDic, thread));
if (!loop) {
/// 取不到时,创建一个
loop = _CFRunLoopCreate();
CFDictionarySetValue(loopsDic, thread, loop);
/// 注册一个回调,当线程销毁时,顺便也销毁其对应的 RunLoop。
_CFSetTSD(..., thread, loop, __CFFinalizeRunLoop);
}
OSSpinLockUnLock(&loopsLock);
return loop;
}
CFRunLoopRef CFRunLoopGetMain() {
return _CFRunLoopGet(pthread_main_thread_np());
}
CFRunLoopRef CFRunLoopGetCurrent() {
return _CFRunLoopGet(pthread_self());
}
基于NSTimer的轮播器什么情况下会被页面滚动暂停,怎样可以不被暂停,为什么?
NSTimer不管用是因为Mode的切换,因为如果我们在主线程使用定时器,此时RunLoop的Mode为 kCFRunLoopDefaultMode,即定时器属于kCFRunLoopDefaultMode,那么此时我们滑动ScrollView时,RunLoop的Mode会切换到UITrackingRunLoopMode,因此在主线程的定时器就不在管用了,调用的方法也就不再执行了,当我们停止滑动时,RunLoop的Mode切换回kCFRunLoopDefaultMode,所有NSTimer就又管用了。若想定时器继续执行,需要将NSTimer 注册为 kCFRunLoopCommonModes 。
延迟执行performSelecter相关方法是怎样被执行的?在子线程中也是一样的吗?
当调用 NSObject 的 performSelecter:afterDelay: 后,实际上其内部会创建一个 Timer 并添加到当前线程的 RunLoop 中。所以如果当前线程没有 RunLoop,则这个方法会失效。 当调用 performSelector:onThread: 时,实际上其会创建一个 Timer 加到对应的线程去,同样的,如果对应线程没有 RunLoop 该方法也会失效。
1
2
3
4
5
6
7
8
9
10
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
NSLog(@"1");
[self performSelector:@selector(test) withObject:nil afterDelay:0];
NSLog(@"2");
});
}
- (void)test {
NSLog(@"3");
}
实际在runloop里面,是一个定时器,但是因为在子线程,runloop是默认没有开启的。所以输出是1 2。
事件响应和手势识别底层处理是一致的吗,为什么?
事件响应: 苹果注册了一个 Source1 (基于 mach port 的) 用来接收系统事件,其回调函数为 __IOHIDEventSystemClientQueueCallback()。 当一个硬件事件(触摸/锁屏/摇晃等)发生后,首先由 IOKit.framework 生成一个 IOHIDEvent 事件并由 SpringBoard 接收。SpringBoard 只接收按键(锁屏/静音等),触摸,加速,接近传感器等几种 Event,随后用 mach port 转发给需要的App进程。随后苹果注册的那个 Source1 就会触发回调,并调用 _UIApplicationHandleEventQueue() 进行应用内部的分发。 _UIApplicationHandleEventQueue() 会把 IOHIDEvent 处理并包装成 UIEvent 进行处理或分发,其中包括识别 UIGesture/处理屏幕旋转/发送给 UIWindow 等。通常事件比如 UIButton 点击、touchesBegin/Move/End/Cancel 事件都是在这个回调中完成的。
手势识别: 当上面的 _UIApplicationHandleEventQueue() 识别了一个手势时,其首先会调用 Cancel 将当前的 touchesBegin/Move/End 系列回调打断。随后系统将对应的 UIGestureRecognizer 标记为待处理。 苹果注册了一个 Observer 监测 BeforeWaiting (Loop即将进入休眠) 事件,这个Observer的回调函数是 _UIGestureRecognizerUpdateObserver(),其内部会获取所有刚被标记为待处理的 GestureRecognizer,并执行GestureRecognizer的回调。 当有 UIGestureRecognizer 的变化(创建/销毁/状态改变)时,这个回调都会进行相应处理。
界面刷新时,是在什么时候会真正执行刷新,为什么会刷新不及时?
当在操作 UI 时,比如改变了 Frame、更新了 UIView/CALayer 的层次时,或者手动调用了 UIView/CALayer 的 setNeedsLayout/setNeedsDisplay方法后,这个 UIView/CALayer 就被标记为待处理,并被提交到一个全局的容器去。
苹果注册了一个 Observer 监听 BeforeWaiting(即将进入休眠) 和 Exit (即将退出Loop) 事件,回调去执行一个很长的函数:_ZN2CA11Transaction17observer_callbackEP19__CFRunLoopObservermPv()。这个函数里会遍历所有待处理的 UIView/CAlayer 以执行实际的绘制和调整,并更新 UI 界面。所以说界面刷新并不一定是在setNeedsLayout相关的代码执行后立刻进行的。
setNeedsLayout/setNeedsDisplay方法都是异步执行的。
setNeedsDisplay: 调用setNeedsDisplay方法会自动调动drawRect! 并不会调用init方法!
setNeedsLayout: 调用setNeedsLayout 方法会调用layoutSubViews!
为什么说layoutSubviews方法在空间都初始化渲染之后才会执行?
因为init不会调用layout,addSubview、setFrame、滚动scroolview的时候会调用
项目程序运行中,总是伴随着多次自动释放池的创建和销毁,这些是在什么时候发生的呢?
系统就是通过@autoreleasepool {}这种方式来为我们创建自动释放池的,一个线程对应一个runloop,系统会为每一个runloop隐式的创建一个自动释放池,所有的autoreleasePool构成一个栈式结构,在每个runloop结束时,当前栈顶的autoreleasePool会被销毁,而且会对其中的每一个对象做一次release(严格来说,是你对这个对象做了几次autorelease就会做几次release,不一定是一次),特别指出,使用容器的block版本的枚举器的时候,系统会自动添加一个autoreleasePool
1
2
3
[array enumerateObjectsUsingBlock:^(id obj, NSUInteger idx, BOOL *stop) {
// 这里被一个局部@autoreleasepool包围着
}];
当我们在子线程上需要执行代理方法或者回调时,怎么确保当前线程没有被销毁?
首先引入一个概念:Event_loop,一般一个线程执行完任务后就会退出,当需要保证该线程不退出,可以通过类似以下方式:开启一个循环,保证线程不退出,这就是Event_loop模型。这是在很多操作系统中都使用的模型,例如OS/iOS中的RunLoop。这种模型最大的作用就是管理事件/消息,在有新消息到来时立刻唤醒处理,没有待处理消息时线程休眠,避免资源浪费。
1
2
3
4
5
6
7
function do_loop() {
initialize();
do {
var message = get_next_message();
process_message(message);
} while (message != quit);
}
开始介绍
一般来说,一个线程执行完任务就会退出,如果我们需要一种机制,让线程能随时处理事件但不退出,那么RunLoop就是这样的一个机制。RunLoop是事件接收和分发机制的一个实现。
RunLoop实际上是一个对象,这个对象在循环中用来处理程序运行过程中出现的各种事件(比如说触摸事件、UI刷新事件、定时器事件、Selector事件),从而保持程序的持续运行;而且在没有事件处理的时候,会进入睡眠模式,从而节省CPU资源,提高程序性能。
程序一启动就会开一个主线程,主线程一开起来就会跑一个主线程对应的RunLoop,RunLoop保证主线程不会被销毁,也就保证了程序的持续运行。其他平台也有类似的RunLoop,Android,Windows。
RunLoop是在程序的入口main函数中开启的
是do while实现的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
通知即将进入runloop
do {
通知将要处理timer和source
处理非延迟的主线程调用
处理source0事件
如果有source1处于ready状态,直接处理这个source1然后跳转去处理消息
通知observers:runloop的线程即将进入休眠
即将进入休眠
等待内核mach_msg事件
等待...
从等待中醒来
处理因timer的唤醒
处理异步方法唤醒,如dispatch_async
处理source1
再次确保是否有同步的方法需要调用
} while();
通知即将退出runloop
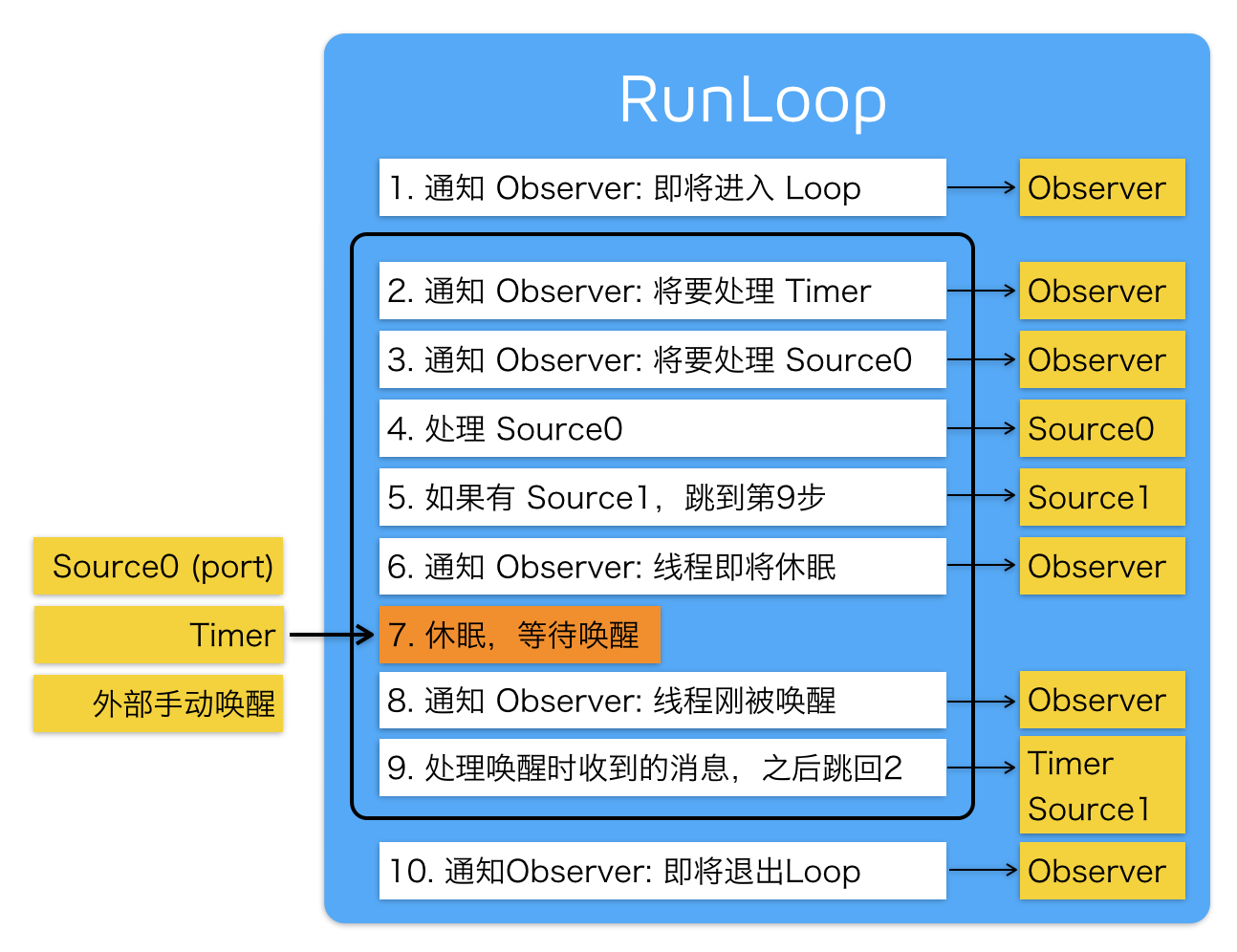
RunLoop和线程
- 每条线程都有唯一的一个与之对应的RunLoop对象
- 主线程的RunLoop已经自动创建好了,子线程的RunLoop需要手动创建
- RunLoop在第一次获取时创建,在线程结束时销毁
[NSRunLoop currentRunLoop]; - Thread包含一个CFRunloop,一个CFRunloop包含多种CFRunloopModel,一种model包含多种CFRunLoopSource事件源(source0和source1),输入源、CFRunloopTimer定时器时间(NSTimer)、CGRunLoopObserver观察者
Core Foundation中关于RunLoop的5个类:
1
2
3
4
5
CFRunLoopRef //获得当前RunLoop和主RunLoop
CFRunLoopModeRef //运行模式,只能选择一种,在不同模式中做不同的操作
CFRunLoopSourceRef //事件源,输入源
CFRunLoopTimerRef //定时器时间
CFRunLoopObserverRef //观察者
CFRunLoopRef
线程刚创建时并没有 RunLoop,如果你不主动获取,那它一直都不会有。RunLoop 的创建是发生在第一次获取时,RunLoop 的销毁是发生在线程结束时。你只能在一个线程的内部获取其 RunLoop(主线程除外)。
[NSRunLoop currentRunLoop];方法调用时,会先看一下字典里有没有存子线程相对用的RunLoop,如果有则直接返回RunLoop,如果没有则会创建一个,并将与之对应的子线程存入字典中。
CFRunLoopModeRef
一个RunLoop包含若干个mode,每个mode又包含若干source、timer、observer。每次调用RunLoop的主函数时,只能指定其中一个mode,这个mode被称作currentmode。如果需要切换mode,只能退出loop,在重新指定一个mode进入。这样做主要是为了分隔开不同组的source、timer、observer,让其互不影响。
各种mode
- kCFRunLoopDefaultMode:App的默认Mode,通常主线程是在这个Mode下运行
- UITrackingRunLoopMode:界面跟踪 Mode,用于 ScrollView 追踪触摸滑动,保证界面滑动时不受其他 Mode 影响
- UIInitializationRunLoopMode: 在刚启动 App 时第进入的第一个 Mode,启动完成后就不再使用
- GSEventReceiveRunLoopMode: 接受系统事件的内部 Mode,通常用不到
- kCFRunLoopCommonModes: 这是一个占位用的Mode,作为标记kCFRunLoopDefaultMode和UITrackingRunLoopMode用,并不是一种真正的Mode
CFRunLoopSourceRef
Source类型:
Source0:用户主动触发的事件(点击button或是点击屏幕)–非基于Port的
Source1:通过内核和其他线程相互发送消息(与内核相关)–基于Port的
注意:Source1在处理的时候回分发一些操作给Source0去处理
CFRunLoopTimer
NSTimer是对RunLoopTimer的封装
CFRunLoopObserverRef
CFRunLoopObserverRef是观察者,能够监听RunLoop的状态改变。
1
2
3
4
5
6
7
kCFRunLoopEntry = (1UL << 0), // 即将进入RunLoop
kCFRunLoopBeforeTimers = (1UL << 1), // 即将处理Timer
kCFRunLoopBeforeSources = (1UL << 2), // 即将处理Source
kCFRunLoopBeforeWaiting = (1UL << 5), //即将进入休眠
kCFRunLoopAfterWaiting = (1UL << 6),// 刚从休眠中唤醒
kCFRunLoopExit = (1UL << 7),// 即将退出RunLoop
kCFRunLoopAllActivities = 0x0FFFFFFFU
runloop退出
主线程销毁Runloop退出
Mode中有一些Timer, Source, Observer, 这些保证Mode不为空时保证Runloop没有空转并且是在运行的,当Mode中为空的时候,Runloop会立刻退出。
我们在启动Runloop的时候可以设置什么时候停止。
1 2 3 4 5 6 7 8 9
/// 用DefaultMode启动 void CFRunLoopRun(void) { CFRunLoopRunSpecific(CFRunLoopGetCurrent(), kCFRunLoopDefaultMode, 1.0e10, false); } /// 用指定的Mode启动,允许设置RunLoop超时时间 int CFRunLoopRunInMode(CFStringRef modeName, CFTimeInterval seconds, Boolean stopAfterHandle) { return CFRunLoopRunSpecific(CFRunLoopGetCurrent(), modeName, seconds, returnAfterSourceHandled); }
autoreleasepool
线程和AutoReleasePool NSthread和AutoReleasePool
每一个线程都会维护自己的AutoReleasePool,而每一个AutoReleasePool都会对应唯一一个线程,但是线程可以对应多个AutoReleasePool。
线程是在线程结束的时候,调用exit之后去执行释放操作
主线程NSRunLoop和AutoReleasePool
AutoReleasePool与RunLoop 与线程是一一对应的关系,AutoReleasePool在RunLoop在开始迭代时做push操作,在RunLoop休眠或者迭代结束时做pop操作。
APP启动后,系统会在主线程Runloop里注册两个observer,回调都是autoReleasePoolHandler()
第一个Observer监视的事件是Entry(即将进入Loop),其回调内会调用autoreleasePoolPush()创建自动释放池。
第二个Observer监视两个事件:BeforeWaiting(准备进入休眠)时调用autoreleasePoolPop()和autorealeasePoolPush()释放旧的池并创建新的池;Exit(即将推出Loop)时调用autoreleasePoolPop()来释放自动释放池。
autoreleasePool里的autorelease对象的加入是在runloop事件中,autoreleasePool里的autorelease对象的释放是在autoreleasePool休眠或者迭代结束时
自动释放池是由 AutoreleasePoolPage 以双向链表的方式实现的
当对象调用 autorelease 方法时,会将对象加入 AutoreleasePoolPage 的栈中
调用 AutoreleasePoolPage::pop 方法会向栈中的对象发送 release 消息
子线程NSRunLoop和AutoReleasePool
子线程在使用autorelease对象的时候,会懒加载出来一个AutoreleasePoolPage,然后将对象插入进去。
autorelease对象在什么时候释放的呢?也就说AutoreleasePoolPage在什么时候调用了pop方法?
其实在上面创建一个NSThread的时候,在调用[NSthread exit]的时候,会释放当前资源,也就是把当前线程关联的autoReleasePool释放掉,而在这里当RunLoop执行完成退出的时候,也会执行pop方法,这就说明了为什么在子线程当中,我们没有显示的调用pop,它也能释放当前AutoreleasePool的资源的原因
常见问题
Autoreleasepool 与 Runloop 的关系?
答:主线程默认为我们开启 Runloop,Runloop 会自动帮我们创建Autoreleasepool,并进行Push、Pop 等操作来进行内存管理
ARC 下什么样的对象由 Autoreleasepool 管理?
答:alloc/new/copy/mutableCopy开始的方法进行初始化时,会生成并持有对象(也就是不需要pool管理,系统会自动的帮他在合适位置release)。其他方式例如id obj = [NSMutableArray array];会自动将返回值的对象注册到autorealeasepool,代码等效于:
1
2
3
@autorealsepool{
id __autorealeasing obj = [NSMutableArray array];
}
第二种:id的指针或对象的指针在没有显式指定时会被附加上__autorealeasing修饰符
1
2
3
+ (nullable instancetype)stringWithContentsOfURL:(NSURL *)url
encoding:(NSStringEncoding)enc
error:(NSError **)error;
等价于
1
2
3
NSString *str = [NSString stringWithContentsOfURL:
encoding:
error:<#(NSError * _Nullable __autoreleasing * _Nullable)#>]
子线程默认不会开启 Runloop,那出现 Autorelease 对象如何处理?不手动处理会内存泄漏吗?
答:会走进autoreleaseNoPage中,然后新建一个poolpage
Autorelease对象什么时候释放?
答:当前线程结束,执行pop
Autorelease & AutoreleasePool 自动释放池的前世今生 —- 深入解析 autoreleasepool
frame和bounds
- frame不管对于位置还是大小,改变的都是自己本身
- frame的位置是以父视图的坐标系为参照,从而确定当前视图在父视图中的位置
- frame的大小改变时,当前视图的左上角位置不会发生改变,只是大小发生改变
- bounds改变位置时,改变的是子视图的位置,自身没有影响;其实就是改变了本身的坐标系原点,默认本身坐标系的原点是左上角
- bounds的大小改变时,当前视图的中心点不会发生改变,当前视图的大小发生改变,看起来效果就想缩放一样
- 旋转的时候,frame的size和bounds的size是不等的
iOS frame和Bounds 以及frame和bounds区别
GCD 多线程
// 串行队列的创建方法
dispatch_queue_t queue = dispatch_queue_create(“net.bujige.testQueue”, DISPATCH_QUEUE_SERIAL);
// 并发队列的创建方法
dispatch_queue_t queue = dispatch_queue_create(“net.bujige.testQueue”, DISPATCH_QUEUE_CONCURRENT);
dispatch_get_main_queue() 主队列 串行
dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0) 全局并发队列
dispatch_source_t 定时器相关 set_timer set_event_hander cancel才能停止循环 dispatch_resume启动
dispatch_semaphore_create 信号量 wait等signal 信号,wait可以设置超时时间
dispatch_barrier_async
dispatch_group notiffy等待所有进入group的方法执行完才调用;wait等group执行完才会往下执行;enter leave
dispatch_once
dispatch_after
NSOperation
纯OC代码 操作队列,对GCD的封装.它是一个抽象类,只能使用其子类对象。系统提供了两个子类对象,分别是 NSInvocationOperation 和 NSBlockOperation。通常我们自定义 NSOperation 的子类,重写子类的 main 方法,把需要在分线程执行的任务放在 main 方法里。然后把 NSOperation 对象添加到 NSOperationQueue 中,就会自动在分线程执行 main 方法。
NSInvocationOperation是使用 selector 回调并可以传递参数进去,NSBlockOperation是使用 Block
NSBlockOperation通过使用addExecutionBlock使用多线程异步能力
- NSOperation 是对 GCD 的封装,面相对象的类,GCD 只是一组方法 API。
- NSOperation 可以实现一些 GCD 中实现不了,或者实现比较复杂的功能。比如:设置最大并发数,设置线程间的依赖关系。
- 实现某个多线程功能,使用 GCD,简单易用。实现某个多线程模块,使用 NSOperation,方便类的管理。
nonatomic,atomic
nonatomic,非原子性,多线程访问修改不加锁。
atomic,原子性,多线程访问加锁。
iOS 推荐我们使用 nonatomic,移动端的开发没有复杂的多线程场景,不加锁解锁可以提高效率。
系统的可变对象,NSMutableArray,NSMutabelString 都是线程不安全的,多线程修改,需要加锁。
线程的五个状态
初始状态,可运行状态,运行状态,阻塞状态,死亡状态
锁
- OSSpinLock 自旋锁,和线程优先级冲突会导致问题,已被弃用
- os_unfair_lock 取代不安全的OSSpinLock
- pthread_mutex 互斥锁
- NSLock 是对mutex普通锁的封装。pthread_mutex_init(mutex, NULL);
- NSRecursiveLock 是对mutex递归锁的封装,API跟NSLock基本一致
- dispatch_semaphore 信号量
- dispatch_queue(DISPATCH_QUEUE_SERIAL) 串行队列串行执行,实现先后执行,类似锁
- @synchronized 是对mutex递归锁的封装,是个关键字,@synchronized的实现原理 objc_sync_enter、objc_sync_exit
@synchronized()是递归锁,同一线程可重入,只是内部有个持锁计数器而已- 进入@synchronized()代码块时会执行
objc_sync_enter(id obj)加锁 - 核心方法是通过
id2data()来获取到对象锁节点SyncData- 首先从当前线程的私有数据(
快速缓存)中查找 - 从当前线程
整体缓存中查找,检查已拥有锁的线程缓存中是否有匹配的对象 - 从全局静态
listp对象锁链表中查找,并更新线程缓存
- 首先从当前线程的私有数据(
- 退出@synchronized()代码块,执行
objc_sync_enter(id obj)解锁 - 在使用@synchronized(obj){}时,如果obj为nil,就不会加锁,而代码块中的代码依然会正常执行,那就会存在风险
- dispatch_barrier_async
- atomic
在主线程中将同步任务压进主队列中
串行队列中,又嵌套了当前串行队列的同步执行任务就会死锁
串行队列因为宽度为1,会走进方法dispatch_barrier_sync_f中,然后互相等待对方的signal导致死锁dispatch_sync 的分析、dispatch_sync死锁问题研究
这是因为 主队列中追加的同步任务 和 主线程本身的任务 两者之间相互等待,阻塞了 『主队列』,最终造成了主队列所在的线程(主线程)死锁问题。
同步执行(sync):加在添加队列的最后面,只能在当前线程中执行任务,不具备开启新线程的能力。
异步执行(async):立即执行,可以在新线程中执行任务,具备开启新线程的能力
串行队列:每次只有一个任务被执行。让任务一个接着一个地执行。
并发队列:可以让多个任务并发执行。并发队列的并发功能只有在异步(dispatch_async)的方法下才能有效。
假设现在有 5 个人要穿过一道门禁,这道门禁总共有 10 个入口,管理员可以决定同一时间打开几个入口,可以决定同一时间让一个人单独通过还是多个人一起通过。不过默认情况下,管理员只开启一个入口,且一个通道一次只能通过一个人。
- 这个故事里,人好比是 任务,管理员好比是 系统,入口则代表 线程。
- 5 个人表示有 5 个任务,10 个入口代表 10 条线程。
- 串行队列 好比是 5 个人排成一支长队。
- 并发队列 好比是 5 个人排成多支队伍,比如 2 队,或者 3 队。
- 同步任务 好比是管理员只开启了一个入口(当前线程)。
- 异步任务 好比是管理员同时开启了多个入口(当前线程 + 新开的线程)。
- 『异步执行 + 并发队列』 可以理解为:现在管理员开启了多个入口(比如 3 个入口),5 个人排成了多支队伍(比如 3 支队伍),这样这 5 个人就可以 3 个人同时一起穿过门禁了。
- 『同步执行 + 并发队列』 可以理解为:现在管理员只开启了 1 个入口,5 个人排成了多支队伍。虽然这 5 个人排成了多支队伍,但是只开了 1 个入口啊,这 5 个人虽然都想快点过去,但是 1 个入口一次只能过 1 个人,所以大家就只好一个接一个走过去了,表现的结果就是:顺次通过入口。
- 换成 GCD 里的语言就是说:
- 『异步执行 + 并发队列』就是:系统开启了多个线程(主线程+其他子线程),任务可以多个同时运行。
- 『同步执行 + 并发队列』就是:系统只默认开启了一个主线程,没有开启子线程,虽然任务处于并发队列中,但也只能一个接一个执行了。
主队列是个串行队列(dispatch_get_main_queue())
全局队列是并发队列(dispatch_get_global_queue())
『主线程』中,『不同队列』+『不同任务』简单组合的区别:
| 区别 | 并发队列 | 串行队列 | 主队列 |
|---|---|---|---|
| 同步(sync) | 没有开启新线程,串行执行任务 | 没有开启新线程,串行执行任务 | ①死锁卡住不执行 |
| 异步(async) | 有开启新线程,并发执行任务 | 有开启新线程(1条),串行执行任务 | 没有开启新线程,串行执行任务 |
下面锁的异步同步输出情况,2023年面试必考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
// 死锁 在串行主队列中同步执行一个任务
NSLog(@"1");
dispatch_sync(dispatch_get_main_queue(), ^{
NSLog(@"2");
});
NSLog(@"3");
// 原因是因为NSLog(@"2");会等待NSLog(@"3"); 才会执行,但是3 又会等待2的执行完才执行,导致死锁
// dispatch_sync 函数本身是放在主线程中执行的,也就是说他本身也是属于主线程执行任务的一部分。根据主线程的特点:主线程会等主线程上的代码(dispatch_sync)执行完毕之后才会去执行放置到主队列中的 task(NSLog(@"3"););再根据 disptach_sync 函数特点, task 不执行完毕,dispatch_sync 函数不返回。这样,dispatch_sync 为了返回会等 task 执行完毕也就是主线程执行完,而 task 执行又等着主线程上的代码执行完,也即主线程上 dispatch_sync 代码执行完。
// 换成这种写法 在串行主队列中异步执行一个任务
NSLog(@"1");
dispatch_async(dispatch_get_main_queue(), ^{
NSLog(@"2");// 异步执行按理是开启一个新的线程,为什么2没有出现立即执行,例如 1 2 3的输出
// 是因为串行队列队列的宽度就是1,所有任务排成一条队伍,异步执行虽然可以开启一个新的线程的能力,但是只有一条执行的队伍,所以还是依次串行执行,并且dispatch_async不会等NSLog(@"2");执行完才返回,会直接返回,所以会去执行NSLog(@"3")
});
NSLog(@"3");
// 输出 1 3 2 是因为2的输出是放在下一个runloop进行的,
// 在看个例子
dispatch_async(dispatch_get_global_queue(0, 0), ^{
dispatch_sync(dispatch_get_main_queue(), ^{ // 阻塞当前线程,等主线程任务4执行完才会执行1,然后sync返回结果继续执行
NSLog(@"1");
});
NSLog(@"2");
NSLog(@"3");
});
[NSThread sleepForTimeInterval:1];
NSLog(@"4");
// 4 1 2 3,
dispatch_async(dispatch_get_global_queue(0, 0), ^{
dispatch_async(dispatch_get_main_queue(), ^{
NSLog(@"1");
});
NSLog(@"2");
NSLog(@"3");
});
[NSThread sleepForTimeInterval:1];
NSLog(@"4");
// 输出 2 3 4 1,因为global是并行队列,异步执行在并行队列中的任务会立即在一个新线程中执行,所以 2 3,异步主线程的任务会放在主线程当前的任务完成之后再执行,也就是4 1,
// dispatch_async 或者dispatch_sync,除了要考虑他们是否会开启新的线程之外,还应该记住:
// dispatch_async不阻塞当前线程
// dispatch_sync阻塞当前线程
『不同队列』+『不同任务』 组合,以及 『队列中嵌套队列』 使用的区别:
| 区别 | 『异步执行+并发队列』嵌套『同一个并发队列』 | 『同步执行+并发队列』嵌套『同一个并发队列』 | ②『异步执行+串行队列』嵌套『同一个串行队列』 | ③『同步执行+串行队列』嵌套『同一个串行队列』 |
|---|---|---|---|---|
| 同步(sync) | 没有开启新的线程,串行执行任务 | 没有开启新线程,串行执行任务 | 死锁卡住不执行 | 死锁卡住不执行 |
| 异步(async) | 有开启新线程,并发执行任务 | 有开启新线程,并发执行任务 | 有开启新线程(1 条),串行执行任务 | 有开启新线程(1 条),串行执行任务 |
1
2
3
4
5
6
7
8
9
10
11
12
// 死锁
dispatch_queue_t syncQueue = dispatch_queue_create("test.queue5", DISPATCH_QUEUE_SERIAL);
NSLog(@"1");
// dispatch_sync(syncQueue, ^{ // ③ 同步执行 + 串行队列
dispatch_async(syncQueue, ^{ // ② 异步执行 + 串行队列
NSLog(@"2");
dispatch_sync(syncQueue, ^{ // 同步执行 + 当前串行队列
// 追加任务 1
NSLog(@"3");
});
});
NSLog(@"4");
layer和view
- layer没有响应链
- view有响应链
- view中的drawRect其实是layer的代理方法
- view是管理,layer是渲染
- view有个layer属性,可以返回它的主layer实例
- view有个layerClass方法,返回主layer所使用的的类,view的子类可以通过重载这个方法,来让view使用不同的layer来显示
引用计数ARC
ARC 在编译期间,用更底层的C接口实现retain/release/autorelease。在编译器和运行期两部分共同帮助开发者管理内存 每次runloop的时候,都会检查对象的retainCount,如果为0,说明可以释放掉
有些对象如果支持使用 TaggedPointer,苹果会直接将其指针值作为引用计数返回;如果当前设备是 64 位环境并且使用 Objective-C 2.0,那么“一些”对象会使用其 isa 指针的一部分空间来存储它的引用计数;否则 Runtime 会使用一张散列表来管理引用计数。
问题1:引用计数如何存储,TaggedPointer(this指针标识)、NONPOINTER_ISA(19bit保存引用计数)、sidetable(管理引用计算表和weak表)
引用计数原理 iOS内存管理及ARC相关实现学习(源码解析)
Tagged Pointer:64位上的优化,指针的值不再是地址了,而是真正的值。一部分直接保存数据,另一部分作为特殊标记,表示这是一个特别的指针,不指向任何一个地址。
Non-pointer iSA:在64位系统上只需要32位来储存内存地址,而剩下的32位就可以用来做其他的内存管理。isa 的内容不再是类的指针了,而是包含了更多信息,比如引用计数,析构状态,被其他 weak 变量引用情况。
问题5:SideTables、tagged pointer、NoPointerISA
原理, 32位、64位指的是CPU位数,在32位CPU下占4个字节,在64位CPU下是占8个字节的。而指针类型的大小通常也是与CPU位数相关,一个指针所占用的内存在32位CPU下为4个字节,在64位CPU下也是8个字节。32 位和 64 位中的“位”,也叫字长,是 CPU 通用寄存器的数据宽度,是数据传递和处理的基本单位。字长是 CPU 的主要技术指标之一,指的是 CPU 一次能并行处理的二进制位数,字长总是8的整数倍。
获取引用计数源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
// NSObject.mm
- (NSUInteger)retainCount {
return ((id)self)->rootRetainCount();
}
// objc-object.h
// 很好的解释了上面的三个知识点 taggedpointer nonpointer sidetable
inline uintptr_t
objc_object::rootRetainCount()
{
/// http://yulingtianxia.com/blog/2015/12/06/The-Principle-of-Refenrence-Counting/
// 如果是tag pointer 当前指针就是引用计数
if (isTaggedPointer()) return (uintptr_t)this;
sidetable_lock();
isa_t bits = LoadExclusive(&isa.bits);
ClearExclusive(&isa.bits);
// isa 指针(NONPOINTER_ISA)
if (bits.nonpointer) {
uintptr_t rc = 1 + bits.extra_rc;
if (bits.has_sidetable_rc) {
rc += sidetable_getExtraRC_nolock();
}
sidetable_unlock();
return rc;
}
sidetable_unlock();
// sidetable存储
return sidetable_retainCount();
}
load和initialize
load每个类,父类子类分类,在main函数之前都会调用一次,仅此一次
initialize使用的时候才会调用,category覆盖->自身覆盖->父类,分类之间的覆盖看编译的先后顺序
initialize子类没有实现的话,会调用父类的实现
load、initialize方法的区别是什么?他们在Category中的调用顺序?
- 调用方式
- load是根据函数地址调用
- initialize是通过objc_msgSend调用
- 调用时刻
- load是runtime加载类、分类的时候调用(只会调用一次)
- initialize是类第一次接收到消息的时候调用,每一个类只会initialize一次(父类的initialize方法可能会调用多次)
load、initialize调用顺序
- load
先调用类的load a) 先编译的类,优先调用load b) 调用子类的load之前,会优先调用父类的load
再调用分类的load a) 先编译的分类,优先调用load
- intialize
- 先初始化父类
- 再初始化子类(可能最终调用的是父类的initialize方法)
class和struct的区别
https://zhuanlan.zhihu.com/p/47808468
- 默认的继承访问权。class默认的是private,strcut默认的是public。
- 默认访问权限:struct作为数据结构的实现体,它默认的数据访问控制是public的,而class作为对象的实现体,它默认的成员变量访问控制是private的。
- “class”这个关键字还用于定义模板参数,就像“typename”。但关建字“struct”不用于定义模板参数
- class和struct在使用大括号{ }上的区别
关于使用大括号初始化
- class和struct如果定义了构造函数的话,都不能用大括号进行初始化
- 如果没有定义构造函数,struct可以用大括号初始化。
- 如果没有定义构造函数,且所有成员变量全是public的话,class可以用大括号初始化
离屏渲染
在使用圆角、阴影和遮罩等视图功能的时候,图像属性的混合体被指定为在未与合成之前不能直接在屏幕中绘制,所以就需要在屏幕外的上下文中渲染,即离屏渲染
卡顿原因:离屏渲染之所以会特别消耗性能,是因为要创建一个屏幕外的缓冲区,然后从当屏缓冲区切换到屏幕外的缓冲区,然后再完成渲染;其中,创建缓冲区和切换上下文最消耗性能,而绘制其实不是性能损耗的主要原因。
触发离屏渲染:
- shouldRasrize 光栅化
- masks 遮罩
- shadows 阴影
- edge antialiasing 抗锯齿
- group opatity 不透明
- 复杂形状设置圆角
- 渐变
离屏渲染指的是在图像绘制到当前屏幕前,需要先进行一次渲染,之后才绘制到当前屏幕。
OpenGL中,GPU屏幕渲染有以下两种形式:
- On-Screen Rendering即当前屏幕渲染,指的是GPU的渲染操作是在当前用于显示的屏幕缓冲区中进行。
- Off-Screen Rendering即离屏渲染,指的是GPU在当前屏幕缓冲区以外新开辟一个缓冲区进行渲染操作。
屏幕卡顿解决方案
屏幕卡顿
- 将不相关的耗时的业务逻辑挪动到子线程去计算,不占用主线程资源
- 提前计算好布局,cellHeight计算好之后就缓存起来,等待下一次调用
- 部分那种只有图片的模块,在图片加载成功回来之后在显示到主屏幕上,不然会出现空白到出现图片模块的闪烁情况
- SDImage帮忙实现了很好的先取缓存图片在去子线程下载的逻辑
如何优化包大小
https://www.jianshu.com/p/a49d59b01669
- 舍弃armv7
- Generate Debug Symbols NO
- 去除无用的第三方库、代码
- 图片处理,图标尽量都使用网图进行下载
编译过程
- 生成辅助文件,目录结构写入,生成空的.app
- dependency 其他target
- 执行脚本run script
- 编译文件
- 链接文件:将项目中的多个可执行文件合并成一个文件;
- 拷贝资源copy bundled
- 编译 Asset 文件
- pod相关的
- 完成.app包
- 签名
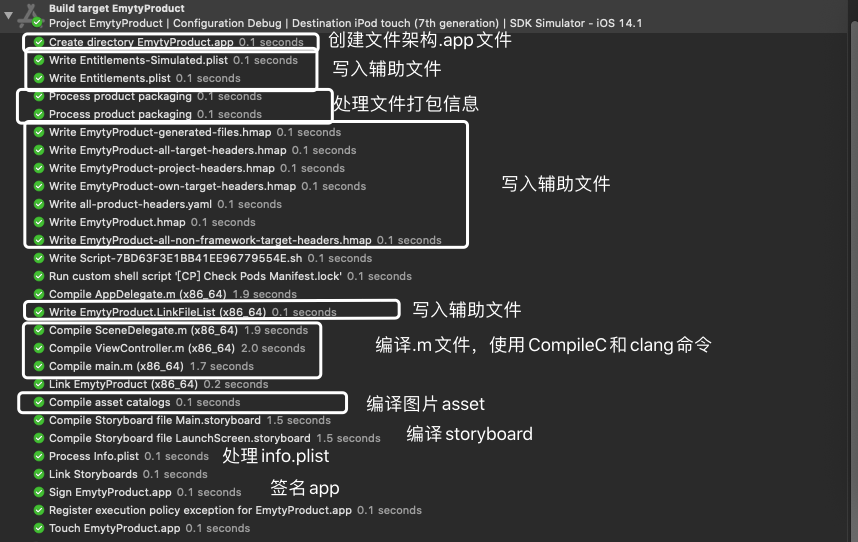
Write auxiliary files 生成辅助文件, .hmap、LinkFileList 文件,用于辅助执行编译用的,可以提高二次编译速度。
编译文件的过程:
预处理:import头文件的导入,宏拆开
代码符号化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
int 'int' [StartOfLine] Loc=<helloworld.c:2:1> identifier 'main' [LeadingSpace] Loc=<helloworld.c:2:5> l_paren '(' Loc=<helloworld.c:2:9> int 'int' Loc=<helloworld.c:2:10> identifier 'argc' [LeadingSpace] Loc=<helloworld.c:2:14> comma ',' Loc=<helloworld.c:2:18> char 'char' [LeadingSpace] Loc=<helloworld.c:2:20> star '*' [LeadingSpace] Loc=<helloworld.c:2:25> identifier 'argv' Loc=<helloworld.c:2:26> l_square '[' Loc=<helloworld.c:2:30> r_square ']' Loc=<helloworld.c:2:31> r_paren ')' Loc=<helloworld.c:2:32> l_brace '{' [StartOfLine] Loc=<helloworld.c:3:1> identifier 'printf' [StartOfLine] [LeadingSpace] Loc=<helloworld.c:4:2> l_paren '(' Loc=<helloworld.c:4:8> string_literal '"Hello World!\n"' Loc=<helloworld.c:4:9> r_paren ')' Loc=<helloworld.c:4:25> semi ';' Loc=<helloworld.c:4:26> return 'return' [StartOfLine] [LeadingSpace] Loc=<helloworld.c:5:2> numeric_constant '0' [LeadingSpace] Loc=<helloworld.c:5:9> semi ';' Loc=<helloworld.c:5:10> r_brace '}' [StartOfLine] Loc=<helloworld.c:6:1> eof '' Loc=<helloworld.c:6:2>
抽象语法树 abstract syntax tree – AST
1 2 3 4 5 6 7 8 9 10 11 12
`-FunctionDecl 0x7f8eaf834bb0 <helloworld.c:2:1, line:6:1> line:2:5 main 'int (int, char **)' |-ParmVarDecl 0x7f8eaf8349b8 <col:10, col:14> col:14 argc 'int' |-ParmVarDecl 0x7f8eaf834aa0 <col:20, col:31> col:26 argv 'char **':'char **' `-CompoundStmt 0x7f8eaf834dd8 <line:3:1, line:6:1> |-CallExpr 0x7f8eaf834d40 <line:4:2, col:25> 'int' | |-ImplicitCastExpr 0x7f8eaf834d28 <col:2> 'int (*)(const char *, ...)' <FunctionToPointerDecay> | | `-DeclRefExpr 0x7f8eaf834c68 <col:2> 'int (const char *, ...)' Function 0x7f8eae836d78 'printf' 'int (const char *, ...)' | `-ImplicitCastExpr 0x7f8eaf834d88 <col:9> 'const char *' <BitCast> | `-ImplicitCastExpr 0x7f8eaf834d70 <col:9> 'char *' <ArrayToPointerDecay> | `-StringLiteral 0x7f8eaf834cc8 <col:9> 'char [14]' lvalue "Hello World!\n" `-ReturnStmt 0x7f8eaf834dc0 <line:5:2, col:9> `-IntegerLiteral 0x7f8eaf834da0 <col:9> 'int' 0
静态检查,语法检查,拼写检查,方法的申明检查(是否实现的检查是在运行时处理)
对AST进行
生成llvm ir
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
; ModuleID = 'helloworld.c' source_filename = "helloworld.c" target datalayout = "e-m:o-i64:64-f80:128-n8:16:32:64-S128" target triple = "x86_64-apple-macosx10.12.0" @.str = private unnamed_addr constant [14 x i8] c"Hello World!\0A\00", align 1 ; Function Attrs: nounwind ssp uwtable define i32 @main(i32, i8**) #0 { %3 = alloca i32, align 4 %4 = alloca i32, align 4 %5 = alloca i8**, align 8 store i32 0, i32* %3, align 4 store i32 %0, i32* %4, align 4 store i8** %1, i8*** %5, align 8 %6 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([14 x i8], [14 x i8]* @.str, i32 0, i32 0)) ret i32 0 } declare i32 @printf(i8*, ...) #1 attributes #0 = { nounwind ssp uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+fxsr,+mmx,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" } attributes #1 = { "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+fxsr,+mmx,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" } !llvm.module.flags = !{!0} !llvm.ident = !{!1} !0 = !{i32 1, !"PIC Level", i32 2} !1 = !{!"Apple LLVM version 8.1.0 (clang-802.0.42)"}
优化,对LLVR IR进行优化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
; ModuleID = 'helloworld.c' source_filename = "helloworld.c" target datalayout = "e-m:o-i64:64-f80:128-n8:16:32:64-S128" target triple = "x86_64-apple-macosx10.12.0" @str = private unnamed_addr constant [13 x i8] c"Hello World!\00" ; Function Attrs: nounwind ssp uwtable define i32 @main(i32, i8** nocapture readnone) local_unnamed_addr #0 { %3 = tail call i32 @puts(i8* getelementptr inbounds ([13 x i8], [13 x i8]* @str, i64 0, i64 0)) ret i32 0 } ; Function Attrs: nounwind declare i32 @puts(i8* nocapture readonly) #1 attributes #0 = { nounwind ssp uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+fxsr,+mmx,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" } attributes #1 = { nounwind } !llvm.module.flags = !{!0} !llvm.ident = !{!1} !0 = !{i32 1, !"PIC Level", i32 2} !1 = !{!"Apple LLVM version 8.1.0 (clang-802.0.42)"}
生成汇编
生成二进制文件可执行文件
启动过程
读取mach-o
遍历解析load-commands部分,找到load_dylinker
加载动态链接器dyld到app进程(dyld也是个mach-o文件)
加载动态库(包括所依赖的所有动态库)- 先加载mach-o的header和command部分。找到load_dylib,加载动态库
Rebase 修复内部的指针地址,使用PIC技术解决ASLD和code sign。address space layout randomization
因为 Mach-O 镜像文件加载到内存中的地址和初始地址不同,
Bind 修正外部指针指向,根据字符串匹配的方式查找符号表
动态库不编译进程序最终的二进制文件中,而是在运行的时候动态的查找调用函数的地址,调用外部符号进行绑定的过程就称作 Binding,比如项目中用到 UIView ,因为 UIView 属于 UIKit 框架,所以需要进行绑定操作
objc runtime
+load __attribute(construct)__
main
willFinishLaunchingWithOptions -> didFinishLaunchingWithOptions
Xcode & Instruments: Measuring Launch time, CPU Usage, Memory Leaks, Energy Impact and Frame Rate
iOS App Launch time analysis and optimizations
dyld 全名 The dynamic link editor,动态链接器
由于 iOS 系统中 UIKit / Foundation 等库每个应用都会通过 dyld 加载到内存中 , 因此 , 为了节约空间 , 苹果将这些系统库放在了一个地方 : 动态库共享缓存区 (dyld shared cache) . ( Mac OS 一样有 ) .
因此 , 类似 NSLog 的函数实现地址 , 并不会也不可能会在我们自己的工程的 Mach-O 中 , 那么我们的工程想要调用 NSLog 方法 , 如何能找到其真实的实现地址呢 ?
其流程如下 :
编译时 : 工程中所有引用了共享缓存区中的系统库方法 , 其指向的地址设置成符号地址 , ( 例如工程中有一个 NSLog , 那么编译时就会在 Mach-O 中创建一个 NSLog 的符号 , 工程中的 NSLog 就指向这个符号,这个符号就是mach-o预留出来的一段空间,其实就是符号表,存放在_DATA数据段中)
运行时 : 当 dyld将应用进程加载到内存中时 , 根据 load commands 中列出的需要加载哪些库文件 , 去做绑定的操作 ( 以 NSLog 为例 , dyld 就会去找到 Foundation 中 NSLog 的真实地址写到 _DATA 段的符号表中 NSLog 的符号上面 )
整个过程其实 PIC 技术 . ( Position Independent Code : 位置代码独立 )
Mach-O
Mach-O可以使用工具MachOView进行查看
分为三个部分:Header、Load Commands和Data
Header 是一个结构体可以在苹果开源的内核源码中找到,这样看起来会更直观,Header 可以指定目标架构,比如是在 arm64 还是 x86 上,用于内核验证,保证平台的正确性等等。
Load Commands 用于指定布局和文件的链接特性,符号表的位置,动态链接器路径等等
类占内存大小
Class其实就是objc_class,详细见方法转发那节
struct和class占内存大小研究见 从C++面试题来学习C++基础
MVC MVP MVVM
MVP: MVP(MVCP)从视图层中分离了行为(事件响应)和状态(属性,用于数据展示),它创建了一个视图的抽象,也就是presenter层,而视图就是P层的『渲染』结果。P层中包含所有的视图渲染需要的动态信息,包括视图的内容(text、color)、组件是否启用(enable),除此之外还会将一些方法暴露给视图用于某些事件的响应。
VC层:view的布局和组装、view的生命周期控制、通知各个P层去获取数据然后渲染到view上面展示
controller层:生成view,实现view的代理和数据源、绑定view和presenter、调用presenter执行业务逻辑
model层:和MVC的model层类似
view层:监听P层的数据更新通知, 刷新页面展示.(MVC里由C层负责)、在点击事件触发时, 调用P层的对应方法, 并对方法执行结果进行展示.(MVC里由C层负责)、界面元素布局和动画、反馈用户操作
Presenter层职责:实现view的事件处理逻辑,暴露相应的接口给view的事件调用、调用model的接口获取数据,然后加工数据,封装成view可以直接用来显示的数据和状态、处理界面之间的跳转(这个根据实际情况来确定放在P还是C)
MVVM:
从MVP发展过来,多了数据绑定(M VM CV - MCVVM) VM其实就会P
Binder层最好的应用就是RAC(ReactiveCocoa)
Runtime相关
runtime涉及的知识点挺多的,消息转发,is_a考点,runtime.h的使用(swizzle),网上涉及的研究文章一堆,我这里贴一些
什么是runtime
runtime在oc中,是由C、C++、汇编编写的一套为OC提供运行时功能的api,就是将代码装载在内存中,在需要的时候进行调用。oc中的消息转发机制就是runtime。

从上图可以看到OC其实是对runtime进行了一层封装,归纳起来runtime有三种使用方式:
1、Objective-C code:例如@selector()
2、NSObject的方法:例如NSSelectorFromString()
3、自己的函数api:例如sel_registerName
能否向编译后得到的类中增加实例变量?能否向运行时创建的类中添加实例变量?为什么?
不能向编译后得到的类中增加实例变量。因为编译后的类已经注册在 runtime 中,类结构体中的 objc_ivar_list 实例变量的链表和 instance_size 实例变量的内存大小已经确定,同时 runtime 会调用 class_setIvarLayout 或 class_setWeakIvarLayout 来处理 strong weak 引用。所以不能向存在的类中添加实例变量。
能向运行时创建的类中添加实例变量。运行时创建的类是可以添加实例变量,调用 class_addIvar 函数。但是得在调用 objc_allocateClassPair 之后,objc_registerClassPair 之前,原因同上。
runtime如何实现weak属性
hash全局表,weak指向的对象内存地址作为key,用所有指向该对象的weak指针表作为value。当此对象的引用计数为0的时候会dealloc,假如该对象的内存地址是a,会在weak表中搜索,找到所有以a为key的weak对象,从而设置为nil。
NSString*obj=[[NSData alloc] init];
编译时是 NSString 的类型;运行时是 NSData 类型的对象
Method Swizzle 使用陷阱
常见的内存问题
循环引用问题
- delegate 使用weak
- block 使用@weakify(self)
- nstimer
- 使用block和weakify的形式
- 使用中间类,让NSTimer定时中的方法由中间类转发给target执行.中间类弱持有target
- 使用消息转发的NSProxy forwardInvocation和methodSignatureForSelector
- 使用dispatch_source_t DispatchTimerSource
内存优化
栈区(stack):线性结构,内存连续,系统自己管理内存,程序运行记录,每个线程,也就是每个执行序列各有一个(看crash log最容易理解),都是编译的时候能确定好的,还有一个特点就是这里面的数据可以不用指针,也不会丢。
堆区(heap):链式结构,内存不连续,最灵活的内存区,用途多多,动态分配和释放,编译时不能提前确定,我们的Objective-C对象都是这么来的,都存在这里,通常堆中的对象都是以指针来访问的,指针从线程栈中来,但不独属于某个线程,堆也是对复杂的运行时处理的基础支持,还有就是ARC还是MRC、“谁分配谁释放”说的都是堆上对象的管理。
静态区(全局区)(bss):初始化数据,简单理解就是有初始值的变量、常量。
常量区(data):未初始化数据,只声明未给值的变量,运行前统统为0,之所以单独分出来,是出于性能的考虑,因为这些东西都是0,没必要放在程序包里,也不用copy。
代码区(text):最静态的,就是只读的东西,存储代码。
内存泄露检查手法
https://wereadteam.github.io/2016/02/22/MLeaksFinder/
xcode静态分析 Analyze
xcode的instrument动态分析 Leaks
MLeaksFinder
MLeaksFinder 一开始从 UIViewController 入手。我们知道,当一个 UIViewController 被 pop 或 dismiss 后,该 UIViewController 包括它的 view,view 的 subviews 等等将很快被释放(除非你把它设计成单例,或者持有它的强引用,但一般很少这样做)。于是,我们只需在一个 ViewController 被 pop 或 dismiss 一小段时间后,看看该 UIViewController,它的 view,view 的 subviews 等等是否还存在。
NSTimer
nstimer与runloop配合使用
两种初始化NSTimer的方法
1
2
3
4
5
6
// 方法1
self.timer = [NSTimer scheduledTimerWithTimeInterval:1.0 target:self selector:@selector(timerFired) userInfo:nil repeats:YES];
// 方法2
self.timer = [NSTimer timerWithTimeInterval:1.0 target:self selector:@selector(timerFired) userInfo:nil repeats:YES];
[[NSRunLoop mainRunLoop] addTimer:self.timer forMode:NSDefaultRunLoopMode];
a. 两个方法等价
b. 第一个是自动添加到当前线程的Runloop中
c. Default模式在触发滑动屏幕,系统会自动切换到Tracking模式导致添加在这个runloop中的方法会不被执行,这是需要改为使用Common模式,common模式等效于default和tracking的结合。
[NSTimer timerWithTimeInterval:1.0 target:weakSelf
使用weakSelf的这种形式,其实在内部还是会转为strong
并非循环引用造成的内存泄露,而是timer还在运行无法释放让持有住的target也无法被释放
NSTimer是对RunLoopTimer的封装
category和extension
extension在编译期决定,它就是类的一部分,在编译期和头文件里的@interface以及实现文件里的@implement一起形成一个完整的类。
category在运行期决定。
这样就推导出,extension可以添加实例变量,但是category不行,因为运行期类的instance_size和ivar_list都已经确定了
category可以为系统的方法添加方法和使用关联对象的方式添加属性,extension不行; objc_setAssociatedObject, objc_getAssociatedObject
category添加和原类相同的方法的时候,不是替换,而是两个都存在,只是在运行时查找方法的时候是顺着方法列表的顺序查找的,分类的方法在原来的方法前面
在类的+load方法调用的时候,我们可以调用category中声明的方法,因为附加category到类的工作会先于+load方法的执行
+load的执行顺序是先类,后category,而category的+load执行顺序是根据编译顺序决定的。
但是关联对象又是存在什么地方呢? 如何存储? 对象销毁时候如何处理关联对象呢?
所有关联对象都由AssociationsManager管理,它是由一个静态AssociationsHashMap来存储所有的关联对象的。这相当于把所有对象的关联对象都存在一个全局map里面。而map的key是这个对象的指针地址,而这个map的value又是另外一个AssociationsHashMap,里面保存了关联对象的kv对。
runtime的销毁对象函数objc_destructInstance里面会判断这个对象有没有关联对象,如果有,会调用_object_remove_assocations做关联对象的清理工作
被问到过,如何向分类中添加一个弱引用属性。主要是字典的NSMapTable和数组的NSHashTable
NSMapTable
1
2
3
4
id delegate = ...;
NSMapTable *mapTable = [NSMapTable mapTableWithKeyOptions:NSMapTableStrongMemory valueOptions:NSMapTableWeakMemory];
[mapTable setObject:delegate forKey:@"foo"];
NSLog(@"Keys: %@", [[mapTable keyEnumerator] allObjects]);
SDWebImage中有一处1 2 3 4 5 6 7 8 9 10 11 12 13 14
@implementation UIView (WebCacheOperation) - (SDOperationsDictionary *)sd_operationDictionary { @synchronized(self) { SDOperationsDictionary *operations = objc_getAssociatedObject(self, &loadOperationKey); if (operations) { return operations; } operations = [[NSMapTable alloc] initWithKeyOptions:NSPointerFunctionsStrongMemory valueOptions:NSPointerFunctionsWeakMemory capacity:0]; objc_setAssociatedObject(self, &loadOperationKey, operations, OBJC_ASSOCIATION_RETAIN_NONATOMIC); return operations; } } @end
查看
NSMapTable的API发现还有以下接口1 2 3 4
+ (NSMapTable<KeyType, ObjectType> *)strongToStrongObjectsMapTable API_AVAILABLE(macos(10.8), ios(6.0), watchos(2.0), tvos(9.0)); + (NSMapTable<KeyType, ObjectType> *)weakToStrongObjectsMapTable API_AVAILABLE(macos(10.8), ios(6.0), watchos(2.0), tvos(9.0)); // entries are not necessarily purged right away when the weak key is reclaimed + (NSMapTable<KeyType, ObjectType> *)strongToWeakObjectsMapTable API_AVAILABLE(macos(10.8), ios(6.0), watchos(2.0), tvos(9.0)); + (NSMapTable<KeyType, ObjectType> *)weakToWeakObjectsMapTable API_AVAILABLE(macos(10.8), ios(6.0), watchos(2.0), tvos(9.0)); // entries are not necessarily purged right away when the weak key or object is reclaimed
NSHashTable
1
2
3
4
5
6
7
8
9
10
11
12
static const NSPointerFunctionsOptions NSHashTableStrongMemory
static const NSPointerFunctionsOptions NSHashTableZeroingWeakMemory
static const NSPointerFunctionsOptions NSHashTableCopyIn
static const NSPointerFunctionsOptions NSHashTableObjectPointerPersonality
static const NSPointerFunctionsOptions NSHashTableWeakMemory
- (instancetype)initWithOptions:(NSPointerFunctionsOptions)options capacity:(NSUInteger)initialCapacity NS_DESIGNATED_INITIALIZER;
// conveniences
+ (NSHashTable<ObjectType> *)hashTableWithOptions:(NSPointerFunctionsOptions)options;
@property以及@synthesize和@dynamic
@property 自动合成getter和setter
@property 有两个对应的词,一个是 @synthesize,一个是 @dynamic。如果 @synthesize 和 @dynamic 都没写,那么默认的就是 @syntheszie var = _var;。
1
2
3
4
5
6
7
8
9
10
@interface ClassA : NSObject
@property(nonatomic, strong) id a;
@end
ClassA *test = ClassA.new;
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
for (int i = 0; i < 100; I ++) {
test.a = NSObject.new; // 会有bad_access崩溃,改成atomic就没事了
}
});
@synthesize 的语义是如果你没有手动实现 setter 方法和 getter 方法,那么编译器会自动为你加上这两个方法。
@dynamic 告诉编译器:属性的 setter 与 getter 方法由用户自己实现,不自动生成。(当然对于 readonly 的属性只需提供 getter 即可)。假如一个属性被声明为 @dynamic var,然后你没有提供 @setter 方法和 @getter 方法,编译的时候没问题,但是当程序运行到 instance.var = someVar,由于缺 setter 方法会导致程序崩溃;或者当运行到 someVar = var 时,由于缺 getter 方法同样会导致崩溃。编译时没问题,运行时才执行相应的方法,这就是所谓的动态绑定。
property中strong和copy的区别、assign和weak
对于不可变对象,如NSString,copy是生成一份新的内存空间,strong是指针复制。strong指向的对象如果被修改,strong的也会被修改。
对于可变对象,如NSMutableArray,使用 copy之后,如果调用add方法就会被奔溃,因为赋值之后生成的新对象是不可变数组
如果希望NSString、NSArray、NSDictionary在赋值之后不会被改变(因为有可能赋值到的是他们的可变类型子类对象),就应该使用copy。
copy还被用来修饰block,在ARC环境下编译器默认会用copy修饰,一般情况下在block需要捕获外界数据时该block就会被分配在堆区,但在MRC环境下由于手动管理引用计数,block一般被分配在栈区,可能会被释放,需要copy到堆区来防止野指针错误。使用strong也行,因为系统隐形的帮忙做了copy操作。
assign修饰对象会产生悬空指针的问题:修饰的对象释放后,指针不会自动置成nil,此时再向对象发消息程序会崩溃
网络相关
开放式系统互联模型(英语:Open System Interconnection Model,缩写:OSI;简称为OSI模型)
- 第七层:应用层 HTTP、HTTPS、FTP、Telnet、SSH、SMTP、POP3
- 第六层:表示层 把数据转换为能与接收者的系统格式兼容并适合传输的格式
- 第五层:会话层 Socket:实现了下面两层的封装
- 第四层:传输层 实现了TCP协议
- 第三层:网络层 实现了IP协议
- 第二层:数据链路层 以太网协议、无线局域网
- 第一层:物理层
socket
socket其实并不是一个协议,它工作在OSI模型会话层(第5层),是为了方便大家直接使用更底层协议(一般是TCP或UDP)而存在的一个抽象层。Socket是对TCP/IP协议的封装,Socket本身并不是协议,而是调用接口(API)。
以太网协议
最底层的以太网协议(Ethernet)规定了电子信号如何组成数据包(packet),解决了子网内部的点对点通信。但是,以太网协议不能解决多个局域网如何互通,这由 IP 协议解决。
IP协议
IP协议定义了一套自己的地址规则,称为IP地址。它实现了路由功能,允许某个局域网的 A 主机,向另一个局域网的 B 主机发送消息。(路由器就是基于 IP 协议。局域网之间要靠路由器连接。)
IP 协议只是一个地址协议,并不保证数据包的完整。如果路由器丢包(比如缓存满了,新进来的数据包就会丢失),就需要发现丢了哪一个包,以及如何重新发送这个包。这就要依靠 TCP 协议。
简单说,TCP 协议的作用是,保证数据通信的完整性和可靠性,防止丢包。
TCP协议
将不同电脑上的数据,必须通过一个共同的协议进行包装,才能实现数据传递和解读。
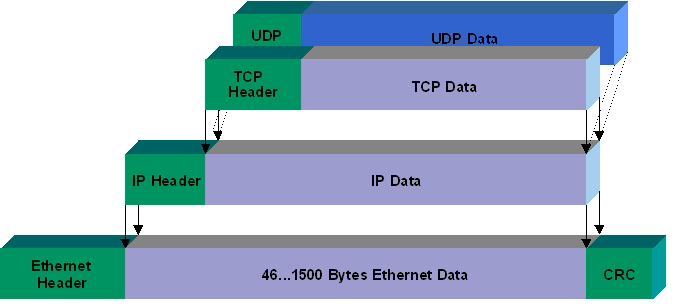
(图片说明:以太网数据包的负载是1500字节,TCP 数据包的负载在1400字节左右。IP 数据包在以太网数据包里面,TCP 数据包在 IP 数据包里面。)
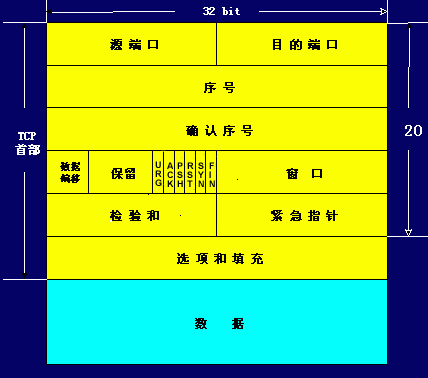
SEQ、SYN、ACK、ISN
- SEQ:sequence number,TCP 协议为每个包编号。一个包1400字节,那么一次性发送大量数据,就必须分成多个包。比如,一个 10MB 的文件,需要发送7100多个包。
- ISN:Initial Sequence Number,第一个包的编号是一个随机数,动态生成的
- SYN:Synchronize Sequence Numbers
- ACK:acknowledgement
三次握手,四次挥手
拥塞控制
滑动窗口
NSArray和NSSet区别
When is it better to use an NSSet over an NSArray?
When the order of the items in the collection is not important, sets offer better performance for finding items in the collection.
The reason is that a set uses hash values to find items (like a dictionary) while an array has to iterate over its entire contents to find a particular object.
IOS性能优化
https://juejin.im/post/5ace078cf265da23994ee493
https://www.jianshu.com/p/05b68c84913a
tableview
- tableviewcell 复用
- 高度缓存
视图层级优化
- 不要动态创建视图,在内存可控的前提下,缓存subview 善用hidden
- 减少subviews个数,用layer绘制元素,少用clearColor maskToBounds和阴影等效果
图片
- 尽量使用png图片
- 优化图片大小,尽量不要使用动态缩放 contentMode
- 尽可能的将多张图片合成一张图片
减少透明view
- 透明view会导致blending,混合像素颜色的计算。两个图层叠加,第一个图层透明,最终的像素颜色会需要将第二个图层也考虑进来。
- 减少离屏渲染
界面渲染过程
https://www.jianshu.com/p/52c72f18e142
runloop有一个60fps的回调,即每16.7ms绘制一次屏幕,所以view的绘制必须要在这个时间内完成。
view内容的绘制是cpu的工作,然后把绘制的内容交给gpu渲染,包括过个view的拼接,纹理的渲染等等,然后显示在屏幕上。
渲染过程:
- UIView的layer层有一个content,指向一块缓存,即backing store
- UIView绘制时,会调用drawRect方法,通过context将数据写入backing store
- 在backing store写完后,通过render server交给gpu 去渲染,将backing store中的bitmap数据显示在屏幕上
https://www.jianshu.com/p/17eb5e095dd7
iOS显示系统:
如何让App渲染的代码定时执行(例如:每秒执行60次)?
iOS 的显示系统是由 VSync 信号驱动的,VSync 信号由硬件时钟生成,每秒钟发出 60 次(这个值取决设备硬件,比如 iPhone 真机上通常是 59.97)。iOS 图形服务接收到 VSync 信号后,会通过 IPC 通知到 App 内。App 的 Runloop 在启动后会注册基于端口的源也就是source1,Vsync信号则通过 mach_port 端口传递过来,同时唤醒runloop,随后 Source1 的回调会驱动整个 App 的动画与显示。
tips:图形服务同APP Process是两个进程,他们之间通信的方式是IPC,了解WKWebview实现机制的同学会发现,WebContent process 同App process进行通信的方式也是通过IPC来实现的。有兴趣的同学可以参考我的另一篇博客:关于wkwebview讲解。
通过mach_port端口发送消息,唤醒Runloop后,做了一些修改view和layer的工作,并提交到全局容器,等待渲染时机到来。
Core Animation 在 RunLoop 中注册了一个 Observer,监听了 BeforeWaiting 和 Exit 事件。当一个触摸事件到来时(也可以理解成Vsync信号唤起),RunLoop 被唤醒,App 中的代码会执行一些操作,比如创建和调整视图层级、设置 UIView 的 frame、修改 CALayer 的透明度、为视图添加一个动画;这些操作最终都会被 CALayer 标记,并通过 CATransaction 提交到一个中间状态去。当上面所有操作结束后,RunLoop 即将进入休眠(或者退出)时,关注该事件的 Observer 都会得到通知。这时 Core Animation 注册的那个 Observer 就会在回调中,把所有的中间状态合并提交到 GPU 去显示;
如果此处有动画,通过 DisplayLink 稳定的刷新机制会不断的唤醒runloop,使得不断的有机会触发observer回调,从而根据时间来不断更新这个动画的属性值并 绘制出来。
注:动画由CADisplayLink来不断唤醒runloop。
png和jpg
png:
- png有透明通道,jpg没有。
- png有手机硬解码加速 无损显示效果好
- png加载速度快,显示效果好
- png在大图片的时候回比jpg大
- xcode也会对png图片进行优化,jpg没有
- png采用的是无损压缩算法
jpg:
高压缩率
适合扫描使用
iOS开发基础UI控件务必使用png, 超大背景图片为了节省大小.可是适当使用jpg. 慎用!
scrollview嵌套的平滑衔接滑动
将scrollview加在tableview的footerview上
用kvo监听tableview的滚动,并联动滚动scrollView
排序算法
https://www.cnblogs.com/onepixel/p/7674659.html
冒泡排序
一次遍历中,将最大的挪到最尾端
if (ai>a(i+1)) ai和aj交换位置
选择排序
每次遍历找到最小元素,然后放到开始位子
插入排序
if (ai>a(i+1)) a(i+1)向前移动到 比前面数大的地方
希尔排序
每 length/2 间隔的数据为一组排序,之后是length/2/2,一直到1
归并排序
递归调用,将数组对半分为左右两组分别排序,然后再合并这两个排序的数组
快速排序 nlog2n
递归调用,以第一个数为基准,进行排序,是小于这个数的都放在左边,大于这个数的都放在右边,然后对左右两边在单独进行这种操作
堆排序
计数排序
输入数据为确定范围的整数,使用字典的形式计数每个出现的key的次数,遍历完之后,再输出
桶排序
基数排序
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。
查找算法
顺序查找
O(n)
二分查找
元素必须是有序的 O(logn)
插值查找 二分查找的改进
元素必须是有序的 O(log2(log2n))
mid=(low+high)/2 mid=low+1/2*(high-low)
改为
mid=low+(key-a[low])/(a[high]-a[low]
斐波那锲查找 二分查找的改进
元素必须是有序的 O(logn)
二叉树查找(二叉搜索树)
中序遍历是个有序数组
平衡查找树
new和alloc/init的区别
https://www.jianshu.com/p/eedd3a88fbf1
alloc分配内存的时候使用了zone,它是给对象分配内存的时候,把关联的对象分配到一个相邻的内存区域内,以便于调用时消耗很少的代价,提升了程序处理速度;
采用new的方式只能采用默认的init方法完成初始化,而不能用其他定制的initXXX方法
简而言之,new和alloc/init在功能上几乎是一致的,分配内存并完成初始化。区别在于,采用new的方式只能采用默认的init方法完成初始化,采用alloc的方式可以用其他定制的初始化方法。
imageName和imageWithContentsOfFile的区别
https://blog.csdn.net/weixin_30781631/article/details/98057656
使用imageName:加载图片
加载内存当中之后,会一直停留在内存当中,不会随着对象销毁而销毁
加载进去图片之后,占用的内存归系统管理,我们无法管理
相同的图片,图片不会重复加载
加载到内存当中后,占据内存空间较大
使用imageWithContentsOfFile:加载图片
加载到内存当中后,占据内存空间较小
相同的图片会被重复加载内存当中
对象销毁的时候,加载到内存中图片会随着一起销毁
总结:
如果图片较小,并且使用频繁的图片使用imageName:来加载(按钮图标/主页里面图片)
如果图片较大,并且使用较少,使用imageWithContentsOfFile:来加载(Imageview动画/版本新特性/相册)
oc 类簇
https://juejin.im/post/6844903912386854926
NSArray: [@[] class] __NSArray0; [@[@1] class] __NSArrayI ; [@[@1, @2] class] __NSSingleObjectArrayI
NSMutableArray:__NSArrayM
NSMutableDictionary: __NSDictionaryM
NSAttributedString: NSConcreteAttributedString
静态库动态库区别
https://blog.csdn.net/lvxiangan/article/details/43115131
https://juejin.cn/post/7049803824214573086
静态库:链接时完整的拷贝至可执行文件中,被多次使用就有多分冗余拷贝
动态库:链接时不复制,程序运行时由系统动态加载到内存,供程序调用,系统只加载一次,多个程序共用,节省内存。
.a和自己的.framework是静态库
.dylib和系统的.framework是动态库,例如nslog函数的基础库
.a 是一个纯二进制文件,.framework中出了二进制文件还有资源文件
.a + .h +sourceFile = .framework
什么是静态库?
静态库是静态链接库;是多个目标文件经过压缩打包后形成的文件包。以下都是静态库的类型
Windows 的 .lib
Linux 的 .a
MacOS 独有的 .framework
什么是动态库?
动态库是动态链接库,是实现共享函数库的一种方式。
动态库在编译的时候不会被拷贝到目标程序中,目标程序只会存储下动态库的引用。
真正用到动态库内的函数时才会去查找 - 绑定 - 使用函数。
动态库的格式有:.framework、.dylib、.tbd……
动态库和静态库的区别
静态库
在编译时加载
优点:代码装载和执行速度比动态库快。
缺点:浪费内存和磁盘空间,模块更新困难。
动态库
在运行时加载
优点:体积比静态库小很多,更加节省内存。
缺点:代码装载和执行速度比静态库慢。
备注
体积小于最小单位16k的静态库编译出来的动态库体积会等于16k。
换成动态库会导致⼀些速度变低,但是会通过延迟绑定(Lazy Binding)技术优化。
延迟绑定:首次使用的时候查找并记录方法的内存地址,后续调用就可以省略查找流程。
动态库、静态库、framework是什么关系?
库是已经编译完成的二进制文件。
代码需要提供给外部使用又不想代码被更改,就可以把代码封装成库,只暴露头文件以供调用。
希望提高编译速度,可以把部分代码封装成库,编译时只需要链接。
库都是需要链接的,链接库的方式有静态和动态,所以就产生了静态库和动态库。
一张图片加载显示到屏幕上的整个过程
https://juejin.cn/post/6844903794929745933
下载图片,cpu进行解压缩图片,计算图片frame,然后交由gpu,gpu获取图片坐标,将坐标交给顶点着色器(顶点计算),光栅化,片元着色器计算(计算每个像素点最终的颜色),最后从帧缓冲区渲染到屏幕上
图片渲染到屏幕的过程: 读取文件->计算Frame->图片解码->解码后纹理图片位图数据通过数据总线交给GPU->GPU获取图片Frame->顶点变换计算->光栅化->根据纹理坐标获取每个像素点的颜色值(如果出现透明值需要将每个像素点的颜色*透明度值)->渲染到帧缓存区->渲染到屏幕
假设我们使用 +imageWithContentsOfFile: 方法从磁盘中加载一张图片,这个时候的图片并没有解压缩;
然后将生成的 UIImage 赋值给 UIImageView ;
接着一个隐式的 CATransaction 捕获到了 UIImageView 图层树的变化;
- 在主线程的下一个 runloop 到来时,Core Animation 提交了这个隐式的 transaction ,这个过程可能会对图片进行 copy 操作,而受图片是否字节对齐等因素的影响,这个 copy 操作可能会涉及以下部分或全部步骤:
- 分配内存缓冲区用于管理文件 IO 和解压缩操作;
- 将文件数据从磁盘读到内存中;
- 将压缩的图片数据解码成未压缩的位图形式,这是一个非常耗时的 CPU 操作;
- 最后 Core Animation 中CALayer使用未压缩的位图数据渲染 UIImageView 的图层
- CPU计算好图片的Frame,对图片解压之后.就会交给GPU来做图片渲染
- 渲染流程
- GPU获取获取图片的坐标
- 将坐标交给顶点着色器(顶点计算)
- 将图片光栅化(获取图片对应屏幕上的像素点)
- 片元着色器计算(计算每个像素点的最终显示的颜色值)
- 从帧缓存区中渲染到屏幕上
cpu和gpu分工
CPU: 计算视图frame,图片解码,需要绘制纹理图片通过数据总线交给GPU
GPU: 纹理混合,顶点变换与计算,像素点的填充计算,渲染到帧缓冲区。
时钟信号:垂直同步信号V-Sync / 水平同步信号H-Sync。
iOS设备双缓冲机制:显示系统通常会引入两个帧缓冲区,双缓冲机制